
图1-1 Hadoop生态系统发展历程
Hadoop的诞生
从个人PC年代到互联网时代,信息技术的快速发展催生了大数据生态体系的发展和演进。
在个人PC年代,计算机存储和处理能力有限,数据量相对较小,主要应用于个人办公、娱乐和简单的数据处理。然而,随着互联网的普及和信息技术的迅猛发展,大量的数据开始被生成和收集,如网页浏览记录、社交媒体数据、传感器数据等。这些海量数据的出现给传统的数据处理方式带来了巨大挑战,需要更强大、高效的处理工具和技术。
在互联网初期,搜索引擎成为人们获取信息的主要途径。随着互联网用户数量的迅速增长,搜索引擎需要处理和分析海量的网页数据,以提供准确、高效的搜索结果。
Yahoo和Google作为当时的主要搜索引擎巨头,面临着处理和存储大规模数据的挑战。他们需要一种可靠、高效的系统来处理这些数据,并能够实现水平扩展,以应对不断增长的数据量。
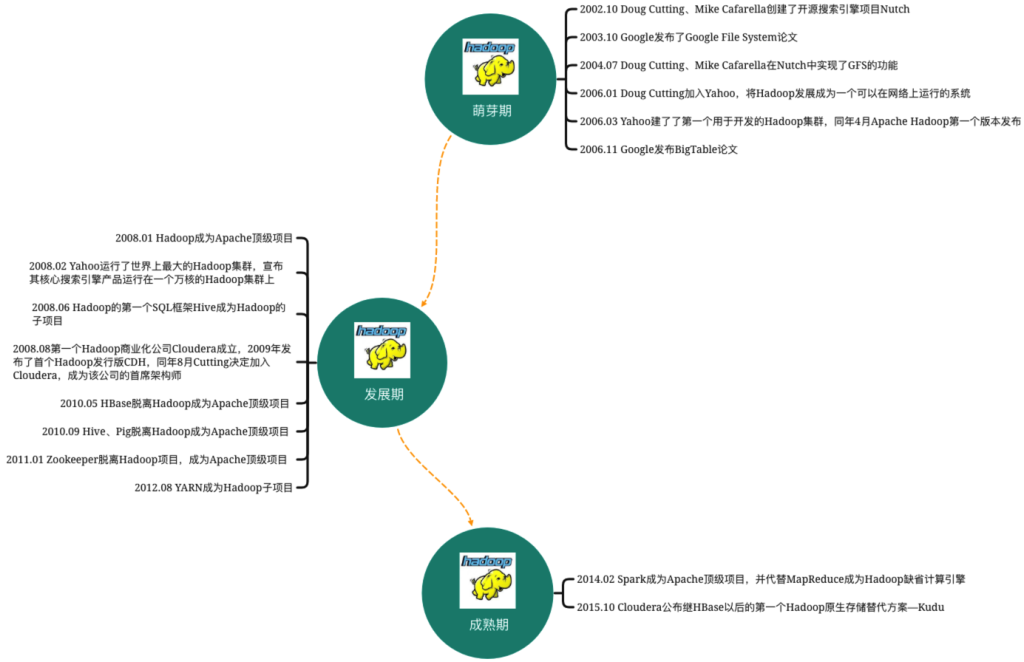
当时互联网第一轮泡沫刚刚结束,Doug Cutting与好友Mike Cafarella认为网络搜索引擎由一个互联网公司垄断十分可怕,他们将掌握信息的入口,因此决定自己开发一个可以代替当时主流搜索产品的开源搜索引擎,该项目命名为Nutch。Nutch致力于提供开源搜索引擎所需的全部工具集。但后来,两位开发者发现这一架构的灵活性不够,只能支持几亿数据的抓取、索引和搜索,不足以解决数十亿网页的搜索问题。
2003年-2004年,Google发表的两篇论文“GFS:The Google File System” 和“MapReduce:Simplifed Data Processing on Large Clusters”,正好为解决海量数据的存储与批量处理提供了方案,Nutch开发者们开始研究Google的GFS(Google File System)和MapReduce计算模型。他们深入研究了GFS和MapReduce论文,并意识到这些技术可以为他们解决处理大规模数据的难题。
最后,Doug Cutting和Mike Cafarella决定创建一个新的项目,即Hadoop,以实现分布式存储和计算的能力。他们从GFS和MapReduce的概念中汲取灵感,并将其作为Hadoop的核心技术,对应到Hadoop的HDFS与MapReduce模块。
2008年02月,Yahoo运行了世界最大的Hadoop集群,宣布其搜索引擎产品部署在一个拥有一万个内核的Hadoop集群上。这也意味着,Hadoop技术已经逐渐稳定并走向成熟。
在此之后,Hadoop生态圈百花齐放,围绕着分布存储HDFS、分布式计算MapReduce,各种在海量数据规模下的解决方案层出不穷。开源大数据的生态得到了极大的发展。
Hadoop当前有三大发行版本,最基础的是Apache Hadoop。
2008年成立的Cloudera是最早将Hadoop商用的公司,为合作伙伴提供Hadoop的商用解决方案,其产品包括CDH、Cloudera Manager、Cloudera Support,Cloudera Manager可以用来集群的软件分发及监控平台的管理,Cloudera Support是咨询培训服务。
Hortonworks的主打产品是Hortonworks Data Platform(HDP),HDP除常见的项目外还包括了一款开源的Hadoop安装和管理系统Ambari,目前HDP开源免费版本没有arm芯片的发行版本,如果使用基于ARM架构的芯片服务器如华为鲲鹏等部署Hadoop,可以考虑一个持续升级的免费Hadoop版本HiDataPlus。
2019年Hortonworks与Cloudera宣布合并,计划共同创建一个更强大的企业级大数据解决方案提供商。合并后的公司以Cloudera的品牌和产品为基础,并整合Hortonworks的技术和资源。
Hive让非技术人员也能用SQL运行MapReduce
在Hadoop出现早期,Facebook面临着海量数据的存储和分析挑战,而Hadoop的分布式计算框架解决方案MapReduce对于非技术人员来说比较复杂,并且需要编写大量的代码才能进行数据处理。
为了解决这个问题,Facebook的团队开发了Hive。Hive使用类似于SQL的查询语言(HiveQL),将用户的查询转化为MapReduce任务,从而隐藏了底层的复杂性。这样,非技术人员也能够通过简单的查询语句来处理和分析大量的数据。Hive还引入了表的概念,将数据组织成类似于关系型数据库的结构,提供了更方便的数据管理和查询方式。
Hive的出现使得大规模数据处理和分析变得更加容易和可行。它成为了Hadoop生态系统中的一个重要组成部分,被广泛应用于各个行业和组织中。除了Facebook,许多其他公司和组织也开始使用Hive来处理和分析他们的大数据。Hive的成功也促使其他类似的数据仓库解决方案出现,如Impala、Presto等,进一步推动了大数据领域的发展。
Pig给开发人员使用的更灵活强大的数据处理工具
与Hive类似,Apache Pig也是为了解决MapReduce开发周期长,API较少并且难用的问题,我们写一个MapReduce程序后,需要编译成jar包,然后提交到HDFS上面,最后执行程序获取结果,这个是很耗时间的,Pig是一个用于分析大型数据集的平台,只需要几行Pig Latin代码就能处理TB级别的数据。
灵活性和表达能力方面,Pig提供了一种更灵活和表达能力更强的编程语言(Pig Latin),可以对数据进行更复杂和灵活的转换和处理。Pig Latin支持的数据流操作和函数更多,可以实现更多样化的分析任务。
Pig在数据转换和清洗方面有优势。Pig Latin的编程模型更适合复杂的数据转换和清洗逻辑,可以更方便地处理数据集的结构变化和复杂的数据处理流程。
在实时处理和迭代计算上,Pig提供了一种在流式数据上进行实时处理和分析的方式,适用于需要实时结果和低延迟的场景。
Pig提供了一种更灵活、更强大和更适合复杂数据处理任务的编程语言和平台。Hive在SQL查询和数据仓库方面更强大,但Pig在数据转换、清洗、实时处理和自定义函数方面可能更具优势。
虽然Pig在易用性、灵活性和可扩展性方面有其优势,但后期出现的Spark、Flink等框架在性能、易于理解使用和集成方面更具优势,所以最后Pig使用场景逐渐压缩,社区活跃度也没那么高。
Zookeeper动物管理员把分布式系统协调管理起来
Zookeeper最初源自雅虎(Yahoo!)研究院的一个研究小组。当时,公司内部的许多大型系统都需要一个类似的分布式协调系统,但这些系统往往存在分布式单点故障(SPOF)的问题。为了解决这个问题,雅虎的开发人员开发了一个通用的、无单点故障的分布式协调框架,以便开发人员能够将精力集中在处理业务逻辑上。
在大数据领域,Hadoop Logo是大象,Hive logo是蜜蜂,Pig Logo是叉着腰的可爱猪;在计算机编程语言领域,Python是蟒蛇;Golang Logo是只囊地鼠,PHP Logo也是头大象,
在项目立项的初期,考虑到许多项目都使用动物的名字进行命名,雅虎也希望为该项目取一个动物的名字。当时,雅虎研究院的首席科学家Raghu Ramakrishnan开玩笑说:“如果继续这样下去,我们这里就会变成一个动物园了!”这个玩笑引起了大家的共鸣,大家纷纷表示可以将该项目称为“动物园管理员”,因为各种以动物命名的分布式组件放在一起,雅虎的整个分布式系统看起来就像一个大型的动物园。而恰好Zookeeper的用途是用于协调分布式环境,于是,Zookeeper的名字就这样诞生了。
Zookeeper被广泛用于分布式系统之间做服务协调和配置管理,比如
- Hadoop用Zookeeper做NameNode的高可用;
- HBase用Zookeeper来保障只有一个当前活跃的HMaster服务,并且hbase:meta元数据表也是存储在Zookeeper节点上;
- Kafka等消息中间件用Zookeeper来进行集群协调和元数据管理;
- Dubbo微服务框架用Zookeeper用来做服务发现,不过现在由于Alibaba Nacos的出现,在业务应用系统上,Zookeeper在配置管理与服务发现的能力,基本已经被Nacos替代;
此外在业务上Zookeeper还可以被用来做分布式锁、存储关键元数据等,但是Zookeeper只适合存储配置、协同相关的关键数据,不适合存储大量数据,如果要存 KV 或者大量的业务数据,就需要用到关系型数据库或者NoSQL,比如HBase。
HBase让大数据随机读写与实时访问走进现实
GFS以及MapReduce虽然提供了大量数据的存储和数据的分析处理能力,但是对于实时数据的随机存取却无能为力,而且GFS适合存储少量的大文件而不适合存储大量的小文件,因为大量的小文件最终会导致元数据的膨胀而可能无法放入主节点的内存。经过多年耕耘,Google在2006年发表了论文“Bigtable: A Distributed Storage System for Structured Data”论文,这篇论文就是HBase的起源,HBase实现了BigTable的架构,如压缩算法、内存操作和布隆过滤器等,HBase弥补了Hadoop随机读写与实时访问的缺陷,使得Hadoop生态系统更加完善。目前HBase在各大公司基本都有使用,如Facebook的消息平台、小米的云服务、阿里的TLog等许多服务组件。
HBase是属于NoSQL范畴,NoSQL是Not only SQL的缩写,泛指非关系型的数据库,如HBase、MangoDB、Cassandra等。与传统的关系型数据库(RDBMS)相比,NoSQL最大的特征就是数据存储不需要一个特定的模式,并具有强大的水平扩展能力。
随着大数据时代的到来,特别是超大规模与高并发的社交类型网站的诞生,传统的关系型数据库已经无法满足这些应用系统架构在横向扩展方面的需求了。
- 并发性:关系型数据库更依赖单机性能,对于上万的QPS,硬盘IO无法支撑,并且关系型数据库除了写数据外还要写索引,而NoSQL如HBase,将磁盘的随机读写转化为内存的随机读写以及磁盘的顺序写入,速度大大提高。并且HBase通过分片可以将一台机器的压力均衡地转移到集群的每一台机器。
- 可扩展性:现在一般的在线系统可用性至少都要求达到99.9%,对于淘宝天猫这种与金钱密切相关的系统,可用性要求就更高了。传统关系型数据库的升级和扩展对于系统的可用性是一个很头疼的问题,可能需要停机迁移数据,重启加载新配置等而且需要运维人员、开发人员、DBA的密切配合,而HBase集群具有线性伸缩、自动容灾和负载均衡的优势,可以很容易地增加或者替换集群节点以扩展集群的存储和计算能力。
- 数据模型:关系型数据库需要为存储的数据预先定义表结构与字段名,而NoSQL无须事先为需要存储的数据定义一个模式,这样可以更容易、更灵活去适配各种类型的非结构化数据。
当然,并不是说NoSQL已经全面优于关系型数据库了,NoSQL相比关系型数据库也有很多缺点,例如HBase不支持多行事务;基于LSM存储模型导致需要读取多个文件来找到需要的数据,这样会牺牲一些读的性能。NoSQL可以说是对关系型数据库的一种补充。
Phoenix为HBase插上SQL的翅膀
HBase支持多种类型的客户端以及HBase Shell,但是客户端的基于Scan的查询仍然较为繁琐以及有一定的门槛,需要具备一定的编程能力的技术人员才能使用,同时HBase只支持行级事务、不支持二级索引,Phoenix解决了HBase支持SQL查询和事务处理的需求。
- 提供SQL查询能力:HBase本身是一个面向列族的NoSQL数据库,不支持SQL查询。而Phoenix将SQL引擎嵌入到HBase之上,使得非技术用户也可以使用熟悉的SQL语句来查询和操作HBase中的数据,无需学习新的查询语言。
- 支持事务处理:Phoenix引入了事务的概念,使得用户可以在HBase上执行原子性、一致性、隔离性和持久性的操作。通过Phoenix的事务支持,用户可以确保数据的完整性和一致性。
- 提供二级索引功能:HBase本身只支持通过主键进行快速查询,而Phoenix提供了二级索引的功能,使得用户可以在非主键列上创建索引,从而实现更灵活和高效的查询。
- 支持连接查询:Phoenix允许用户进行连接查询,即在多个表之间进行关联查询。这为复杂的数据分析和处理提供了便利,使得用户可以更方便地进行跨表查询和分析。
- 提供更高的性能和效率:Phoenix通过在HBase上建立查询优化器和执行引擎,能够对SQL查询进行优化和加速。它使用了多种技术,如编译器优化、查询计划优化和数据预取等,以提供更高的查询性能和更低的延迟。
总体来说,Phoenix为HBase提供了一个简单、高效的SQL引擎,使得用户可以通过SQL查询和操作HBase中的数据,同时支持事务处理、二级索引、连接查询等功能,提高了数据查询和处理的灵活性、性能和效率。
Kudu随机存取与实时分析的卓越融合
HBase和HDFS在大数据处理中各有其优势和局限性。HBase提供了优秀的随机读写性能,适用于实时随机访问的场景,但其批量数据处理的吞吐量较低。相反,HDFS提供了高吞吐量的批量数据处理能力,适用于大规模数据的离线分析,但其随机读写性能相对较弱。
在实际的业务场景中,我们通常需要一个系统既能支持实时随机读写(OLTP),又能支持批量分析(OLAP),以满足实时分析和交互式查询的需求。这就是湖仓一体架构的目标,将数据湖和数据仓库的功能融合到一个统一的架构中。
Kudu作为一种新兴的存储引擎,提供了一种平衡实时随机读写和OLAP实时分析的解决方案。Kudu的定位是”Fast Analytics on Fast Data”,它能够同时支持随机读写和批量数据分析的需求。Kudu可以与上层的计算框架(如Impala、Spark等)紧密结合,提供高速的实时数据访问和分析能力。因此,Kudu被称为HDFS的原生存储替代方案,避免了数据同步和维护多个存储引擎的成本和复杂性。
综上所述,Kudu平衡了HBase和HDFS在随机读写和批量分析方面的性能,提供了一种满足实时分析和交互式查询需求的湖仓一体架构的解决方案。
YARN又一个高效灵活的资源分配与调度引擎
Hadoop 1.0时期,Hadoop包含两个核心模块,HDFS和MapReduce,其中MapReduce由编程模型、运行时环境(JobTracker和 TaskTracker)和数据处理引擎(MapTask 和 ReduceTask)三部分组成,MapReduce同时也充当了资源管理和调度的角色,但其存在一些限制。例如,MapReduce框架只能运行批处理作业,难以支持实时流处理和交互式查询等应用。JobTracker有单点故障问题、框架设计只能执行 MapReduce 任务,不能执行Spark、Flink等计算框架的任务。此外,MapReduce框架的资源管理和调度能力也有限,无法灵活地管理和分配集群资源。
为了解决这些问题,在Hadoop 2.0中,YARN作为一个独立的组件被引入,负责集群资源管理和调度,而MapReduce则成为运行在YARN上的离线处理框架。这样的架构变化带来了显著的优势。
首先,YARN将JobTracker中的资源管理和作业控制分离,使得整个系统更加可靠和稳定,避免了单点故障问题。ResourceManager负责分配集群资源给各个应用程序,而ApplicationMaster则负责管理一个应用程序的资源分配和任务调度。这种分工使得资源的利用更加高效,同时也支持了多个应用程序的并发执行。
其次,YARN的设计还具备出色的可扩展性,使得它能够容纳各种不同类型的计算框架,如Spark、Flink等。这为用户提供了更大的灵活性,使其能够根据自己的需求选择最适合的计算模型。不同的计算框架可以在同一个YARN集群上共享资源,实现资源的高效利用。这种灵活性和可扩展性为用户提供了更多的选择空间,使得他们能够根据具体的业务场景和需求来决定使用哪种计算框架。无论是批处理任务还是实时流处理,YARN都能够提供强大的支持和优化,确保任务的高效执行和可靠性。
Spark将大数据计算引擎推向新的高度
在 Hadoop 时代,MapReduce 就饱受着来自传统关系型数据库领域的争议。相比于数据库领域从二十世纪发展到二十一世纪,经历过几十年的理论和技术沉淀,MapReduce 有太多值得说的缺点了。这一场的争议以MapReduce: A major step backwards开始,以 Spark 的诞生结束。
在Hadoop时代,MapReduce面临来自传统关系型数据库领域的争议。相比于经历几十年的理论和技术沉淀的数据库领域,MapReduce被认为存在许多缺点。这场争议以”MapReduce: A major step backwards”开始,并随着Spark的诞生逐渐结束。
Spark起源于加州大学伯克利学院的AMP实验室,与大多数来自工业界的开源软件不同,Spark是一款来自学术界的产品。Spark吸收了数据库领域和MapReduce的精华,同时摒弃了它们的缺点,从零开始构建了一款大数据计算引擎。Spark的诞生提醒人们,在大数据分析和处理领域,并不只有MapReduce这一种方式,传统的关系型数据库领域的优秀思想也可以借鉴进来。大数据计算引擎进入了百花齐放、百家争鸣的时代,诞生了Impala、Presto、Flink等产品。
Spark是技术和商业结合的最佳典范之一。首先,Spark并没有纠结于自身设计理念相对于MapReduce的优越性,而是关注于当时MapReduce难以解决的机器学习问题。原生的MapReduce由于设计理念的限制,在处理需要大量数据迭代的情况下非常困难,而Spark通过DAG(有向无环图)的设计解决了这个问题,吸引了大量用户,迅速启动了产品。其次,Spark开发者具备独特的眼光,如Spark Streaming、Dataframe等创新产品解决了许多痛点问题,极大地扩展了Spark的应用场景,并形成了像Hadoop一样的生态系统。
在后Hadoop时代,Spark基本取代了MapReduce。作为一款开源产品,Spark社区热情高涨,商业公司也能够依赖它产生足够的利益来持续发展。
Flink实时流与事件驱动的流批一体框架
- 数据处理模型:Spark使用批处理模型,将数据分成离散的批次进行处理,而Flink则使用流处理模型,对连续的数据流进行实时处理。
- 状态管理:在流处理中,Flink具有内置的状态管理机制,可以跨事件和时间进行状态管理,而Spark需要借助外部存储来管理状态。
- 事件时间处理:Flink具有内置的事件时间处理支持,能够处理乱序事件、处理时间窗口和会话窗口等,而Spark的事件时间处理相对较弱。
- 容错性:Flink使用分布式快照机制实现容错,可以保证在故障发生时数据的一致性和可靠性,而Spark则依赖于弹性分布式数据集(RDD)来实现容错。
- 执行引擎:Spark使用基于内存的计算引擎,适用于迭代计算和交互式查询,而Flink使用基于状态一致性的流计算引擎,适用于连续的实时数据处理。
- 扩展性:Flink可以与其他生态系统工具(如Kafka、Hadoop等)无缝集成,而Spark也有类似的集成能力,但Flink在一些数据源/接收器和库的支持方面更加广泛。
- 查询语言:Spark提供了Spark SQL作为SQL查询引擎,而Flink则提供了Flink SQL,两者在SQL查询的功能和性能方面有所差异。
总体而言,Flink更专注于实时流处理和事件驱动的场景,具有更强大的事件时间处理和状态管理能力,而Spark更适用于离线批处理和交互式查询场景,并且具有更广泛的生态系统支持。选择使用哪个框架取决于具体的业务需求和数据处理场景。